
Ya sabemos que hay planetas habitables, y sabemos que hay agua en Marte.
Sabemos también que vamos a tener que rescatar a Matt Damon de cualquiera de esos planetas (evidencias aquí y aquí).
Pero aún así, no logramos hacer push de commits que no entren en conflicto. Aún no logramos evitar que un merge de una tarea no te bloquee otros merge que ya fueron aprobados y necesitás en producción.
Lo primero será contextualizar el post.
Una parte importante de mi trabajo de los últimos 10/15 años ha estado vinculada a ecommerce, muy especialmente con Magento, lo cual no suele parecerse a mantener este blog (o un sitio institucional) actualizado.
En más de una oportunidad me tocó formar parte de proyectos y equipos de importante tamaño y complejidad, por lo que las dificultades aumentaron acompañando esas proporciones.
Me atrevo a decir que he podido ver y disfrutar (y padecer) de diferentes estrategias de branching a lo largo de ese tiempo, y aún cuando se hubieran repetido, los resultados no fueron siempre los mismos.
Las dos estrategias que más he visto son:
En ambos casos, y en particular en proyectos de mayor complejidad, me ha tocado vivenciar (por ser parte directa o sólo un observador) situaciones tales como:
- Conflictos que han impedido un merge prolijo e incluso deployments.
- Bloqueos de dependencias (quizás más relacionado con una mala planificación en las tareas que por la estrategia de branching).
- Infinidad de ramas de tipo feature y release que quedan cual basura en el repositorio (y ni hablar de la mala comunicación que hace que a veces convivan dos o más release branches y alguien cree un PR al branch incorrecto).
¿Algo de esto suena familiar? (porque me consta que pasa en TNT)
No hay dudas que la raíz del problema es la aplicación de la estrategia o el cómo seguimos el workflow. Pero creo que, al mismo tiempo, hay estrategias que pueden prestarse con más ganas a esos problemas de aplicación.
Como ya dejamos claro en el episodio de ¿Qué hacemos con el auth.json?, la respuesta a casi todo es “Depende”. La máxima debería ser que siempre la mejor opción será relativa al contexto en el cual nos encontremos.
Sin dudas, habrá escenarios en los que trabajar sólo con el Git Basic Workflow (usar sólo el branch master y nada más) será suficiente y válido.
Seguramente, una vez que ya haya código en entorno productivo, muchos preferirán (como mínimo) pasa a algo como Git Feature Workflow (que podrá o no incluir un Develop branch) o quizás usar Github Flow.
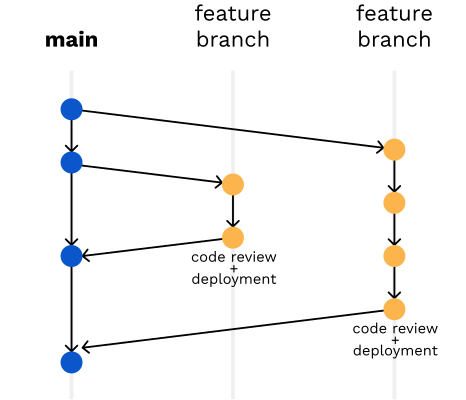
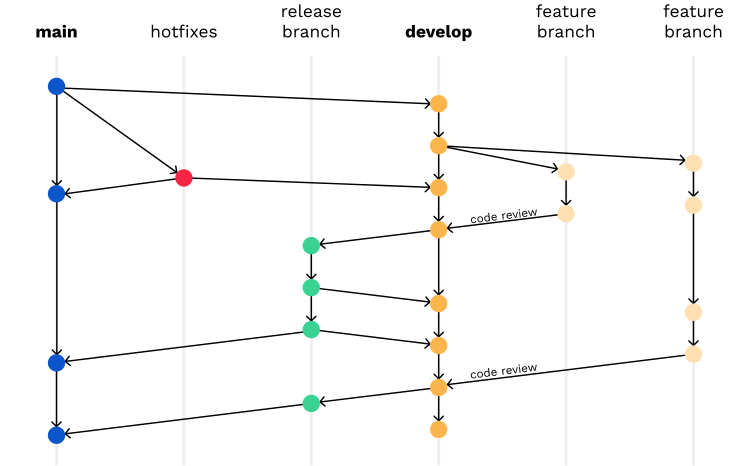
Y de allí saltar quizás a GitFlow o GitLab Flow.
Github Flow es una estrategia que me gusta mucho, aunque se la critica por no poder manejar entornos de forma adecuada (y esto generaría problemas de código no deseado en el entorno no indicado).
Para pequeñas cosas, tal como mencionaba al comienzo (e incluyendo los cambios de código del blog), Github Flow suele funcionar muy bien (más aún cuando se trabaja solo).
Pero si nos encontramos con proyectos con algo más de complejidad y varios developers trabajan al mismo tiempo, la estrategia que me viene dando mayores satisfacciones (y esquivando dolores de cabeza) es la del Trunk-Based Development.
En pocas palabras, se trata de utilizar sólo una rama (trunk) y cada vez que se envíe código, el código tiene que ser deployable. No puede haber código roto (nunca debería, pero esa es otra discusión).
Cuando se alcanza un punto de release, se crea un branch y ese branch se deploya a producción (como alternativa, puede optarse por un tag en lugar de un branch). Si se optara por release branch para el deploy, se supone que (como en la mayoría de las estrategias, los releases viejos deberían eliminarse ya que los branches no son inmutables).
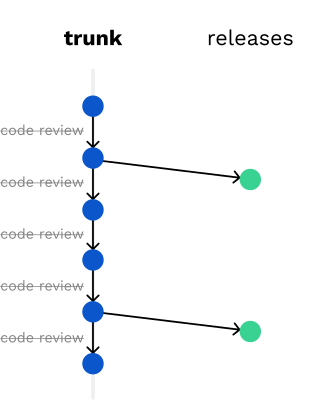
En esta estrategia se sugiere también que si un feature toma algo de tiempo, podemos permitirnos crear branches de muy corta vida que serán mergeados contra el trunk.
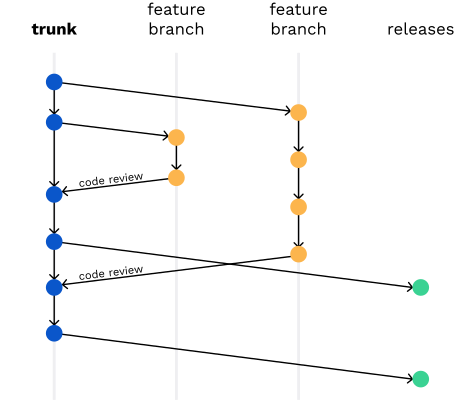
De esta forma, todo el tiempo tenemos código que funciona, todos tenemos el mismo código, y la posibilidad de tener pequeños releases deployables aumenta de forma considerable.
Hay un elemento adicional que hará que esta estrategia funcione mejor, y son los Feature Flag. Al implementar nuestros cambios y teniendo la capacidad de activarlos o no mediante configuraciones, tendremos aún más control sobre el código que se ejecute.
Actualmente he optado por Scaled Trunk-Based Development + Feature Flags como estrategia por defecto (a veces por simplicidad se reemplaza con Github Flow). Y sumado a lo que ya escribí alguna vez sobre Jenkins y los deploys automáticos, el pipeline valida que haya tag antes de deployar a Producción.
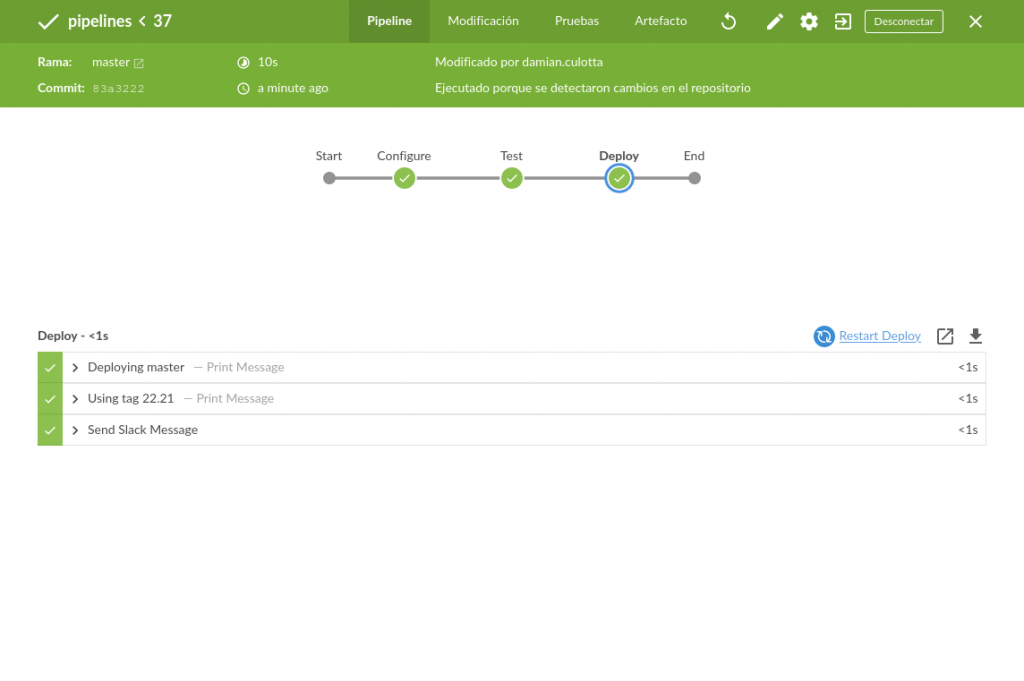
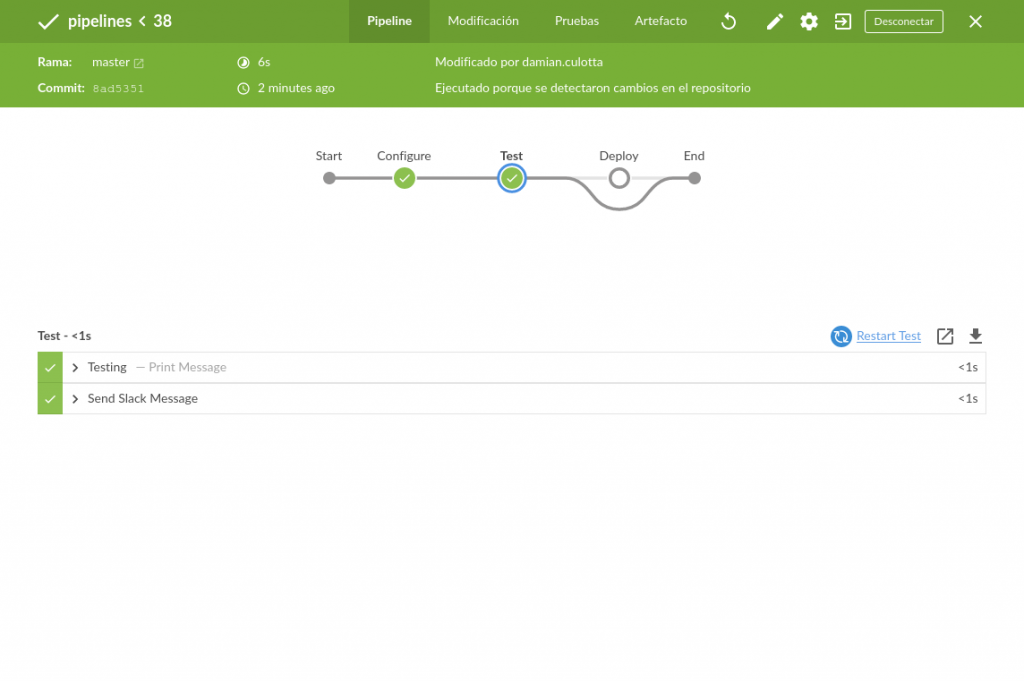
Si no hay tag, no pasa nada en particular.
Créditos: las imágenes de los workflows pertenecen a este post, el cual me ahorró tener que dibujar los ejemplos.